Having worked extensively in games, movies, immersive, and XR including entertainment, corporate and even medical our businesses have seen a wide variety of innovations and opportunities to break boundaries.
One great example is iDrive VR released by Quantum Rehabilitation, the second largest wheelchair manufacturer in the world. The driving simulation took the actual physical chair controls and matched them with the VR controls for a life-like experience learning to drive a power chair. So as a user learns to physically drive a chair, with any type of control they can sit in any kind of chair to drive the VR experience — which technically drives windows. This overcomes the lack of clinicians and in chair experience before users get approved or denied for a chair which is a one-time and final decision.
The work we did for KPMG was focused on interactive multi-user data visualization. Another early product was Volumation was a volumetric capture and processing solution built for more prosumer use.
Before we dive into the technical goodness, there are some important foundations that got Mod Tech Labs to where it is today. To start the CTO, Tim Porter, graduated with a Bachelors of Science in Computer Animation from Full Sail University. He also worked in games and movies including Alice in Wonderland: Through the Looking Glass, Cars, Disney Games, Dreamworks titles, Dave and Busters Augmented Reality experiences and many more.
Mod Tech Labs got its start in Austin, Texas by becoming a venture backed company in 2020 through investment from SputnikATX, and Quansight Futures. Both the CEO, Alex Porter, and CTO, had been Intel Top Innovators since 2017 as well as City of Austin Innovation Award recipients, and went on to be recognized by the Forbes 100, NVIDIA Inception, Technology Leadership through their work at the Consumer Technology Association publishing standards for Limited Mobility and Diversity and Inclusion for XR, and last, but not least in 2022 won a $1M investment from 43North.
From the beginning the MOD core tenets are faster processing, automated systems, universal input and output, and hybrid systems processing including cloud and on-premise.
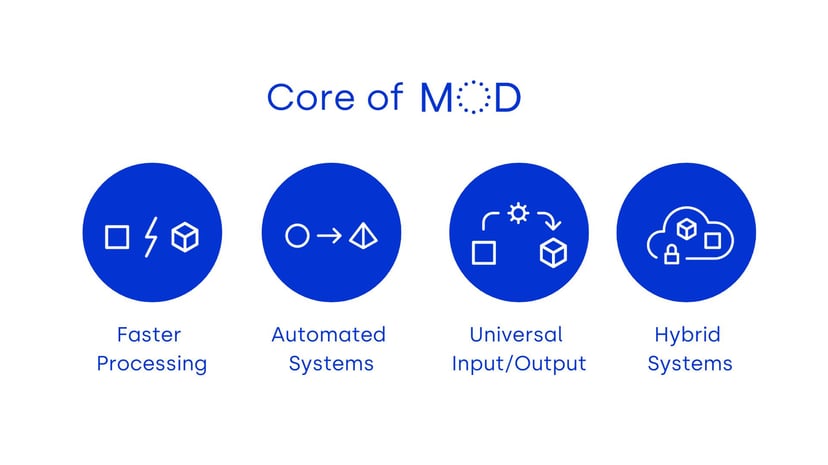
These core features are directly aimed at one of the biggest issues in VFX, the amount of time it takes to do things. Most tasks are fairly manual, even if they do have automated systems, there’s so many stop gaps and inefficient processes that are linear and fragile.
Automated workflows with universal input and output – meaning any imagery data goes into the system including photos, videos, scans, or models and can be output as any open file type like FBX, OBJ, and many more. Proprietary file types make it hard to work between programs and efficiently move data through the workflow so we got rid of that hurdle. Private secure cloud is one option to scale systems as companies take a hybrid approach. There are certifications available to verify security like the Trusted Partner Network(TPN) powered by the Motion Picture Association, allowing for more options and providers. The costs and obstacles to using public GPU instancing, which is especially relevant to imagery data, makes it less attractive to studios that already run on smaller margins though the model is changing with some of the new tools available from NVIDIA. During the pandemic many companies explored pure cloud and found it to be too expensive, the latest products mentioned above will change this dynamic once again.
MOD leverages machine learning to distribute workloads across a cluster making processing much more efficient and faster. As well as training algorithms with proprietary data to create automated secondary maps, the tunable layers of assets that make them fit in each environment, all these parts are integral to making scenes and objects look better and playback on any screen.
MOD is a robust configurable 3D workflow with more than 90 microservices that include image resizing, sharpening, unoptimized mesh and point cloud creation, voxelization, automated color correction, mesh creation, decimation, cleaning remeshing, texture baking, secondary maps, and texture optimization and many more. For a full list of features feel free to reach out to the team to chat.
AI-Powered Automated 3D Workflows
Photos/Models
- Real-time Optimization
- Stage Profiler
- Anomaly Detection
- ML Secondary Maps
- ML Training
- Image Resize
- Image Sharpening
Process
- Retopology
- Photogrammetry Mesh
- Lidar Processing
- Video Decoding
- Color Correction
- Decimation
- Texture Optimization
Playback
- Remeshing
- Mesh Smoothing
- Degrain / Denoise / Deblur
- Point Cloud to Mesh
- Exposure Control
- Image Conversion
Our long term plan is to continue adding more features and make it simple to drag and drop your desired workflow or pick a template and we will automate the rest. Other features that in the works include automated delighting, de-shadowing, cutout tools, auto rigging, full FACs and wraps remeshing, full green screen correction, even automatic rotoscoping. Into FBX file encoding optimization, which actually does a single .fbx file for an entire volumetric capture sequence, including textures and meshes and everything all-in-one including the animation.
This is an automated texture optimization tool that uses machine learning to keep the image scale and quality as it goes along.
The first mesh from that lineup is in 8k, then followed by 4k, 2k, and 1k. The most amazing part is that it’s really hard to tell a massive quality difference between all of these. It is literally going to 1/64th the size from 8k to 1k.
The is the MOD mesh decimator which does a lot of work to ensure that the actual edging and silhouette are kept. Most decimators do a really poor job at that, but MOD solves for it by keeping a silhouette from the scan. Our algorithm balances between the two meshes to create an optimal output which can be seen in the mesh below.
MOD Decimation by MOD on Sketchfab
If you zoom in closely on the figure in the center of the fountain you can see this is a decimator. Most decimators will not provide a quality like this. Based on our machine learning we are able to minimize the mesh by half from 4.49 million down to 2 million, and the quality is phenomenal.
Automated remeshing —does flow mapping along the entire surface. Notice the quadrilation and then the flow linear processing that goes across this asset. The mesh above shows the lines actually run across, and the algorithm understands a certain amount about not only the topology, but the topology flow and how to produce that topology flow to actually produce an awesome result. The lapel of the jacket on the bust is another key example of edging.
Normally when a remesh or optimization is done the artist will state “I want X number of polygons,” but that is not the most effective process. Instead, with MOD: “I want this much crease amount” and say, “I want to make sure that the edges stayed this true to the original,” and that’s how MOD produces higher quality assets.
MOD Remesh by MOD on Sketchfab
Above, notice the first model is the big original raw asset. It is very high res — 1.4 million tris. The second model (MOD Movie Quality Remesh) goes down to 87,000! The quality on the shirt is where to pause and see the mesh to go across seamlessly. Especially if this is not a hero asset. The third model goes down to 28,000 — with similar results. Lastly, a really low res mesh, 13,000 tris. If this is going to be used in a game or something similar, you’ll end up baking in the secondary maps to keep that quality.
Above is automated texture reprojection using a considerable amount of cage work. Normally, when doing a reprojection an artist would say, “I want a cage that is this big — this many units”. The work on this was very specifically to figure out how big a cage was wanted so there is a large amount of work based on the original images and other kinds of setups — like looks based on different angles. MOD does a lot of work to ensure the cage is the appropriate size.
Texture Reprojection — You can see in the Bust Demo the original texture is on the left side. Then the remake is on the right, and it provides the ability to do whatever is wanted with UVs — a very important feature.
And lastly, automated glTF playback, as seen above, has machine learning primarily in the mesh generation.
MOD mesh generation is different from others because of how we find our cameras in three-dimensional space, but also how we use that camera information to provide secondary features once we get past the dense process, which is how we get that higher quality based off of the textual images. This is often lost through most photogrammetric processes. Going from an initial to a high res mesh, and you’re like, “Okay, cool, I want to optimize it some…” and then what do you do with those details?
One of the big ways that a lot of studios do it is they go in and they hand remap over all of it, with different varying brushes. Removing this manual part ends up automating the process. And this, of course, is just glTF on top of it. These (in the video) are super optimized assets. The first one is only 10mb and then the second one is less than 100mb for a full body sequence… that’s it.
Other features like motion blur reduction as well as machine learning color grading innovate with convolutional neural networks, to understand what an asset is. For example, it takes someone’s skin tone and recognizes it as the same asset over time, and then it does all of the style transfer throughout all the scenes. The MOD style transfer tool allows a user to feed it both the image to color grade and the one that you want the grading to come from and it does an intelligent amount of combination between the two of them.
MOD helps entertainment and media companies scale universal 3D content creation with AI-powered automated workflows. The no-code processing platform adds efficiency by automating workflows to clean, refine and enhance 3D content. Using photos, videos, scans, or meshes to make 3D using machine learning enhanced processes make the output better with time and fully customizable. The increase in demand for digital objects, people and places requires automation to scale. Teams can minimize skill requirements, time to deliver, and overall costs to make 3D content with MOD.
Share the article and your thoughts – and please tell us what other topics you would like us to cover.